AI Benchmarks For Mobile Devices And What You Should Know
Making Sense Of Mobile Device Benchmarks That Measure AI And Machine Learning Performance

For those that may be unfamiliar with how machine learning and AI technologies work, we should probably lay a little foundation. This is somewhat oversimplified for the sake of brevity, but should be helpful background nonetheless. It all starts with the concept of Neural Networks (NN). Neural Networks are integral parts of ML and AI, as are the processes of Training and Inference.
Of Neural Networks, Training And Inference
Neural networks, or algorithmic models that are inspired by human brain activity, are initially put through a training phase, before they can draw conclusions on data, or infer anything new from a particular dataset. They are usually trained with large amounts of data, which is filtered through multiple layers to determine something specific about the data, whether it be a certain color or a shape – like an image of a human face, a cat or a dog, for example.
As the dataset is being processed, mathematical functions in the neural network, referred to as neurons, assign weightings to new entries, to determine whether or not a particular piece of data meets a certain criterion. Similar to the way your brain learns the shape of a dog’s face at an early age, which then gives you the ability to determine, “yep, that’s a dog and not a cat.” In this simple example, it boils down to that one binary yes/no function for the end result that is determined by your brain. Similarly, once the neural network training process is complete for the AI model, weightings have been assigned to the entirety of a data set, and it’s all classified and segmented accordingly. The neural network can then intelligently infer things from that data and the resulting AI can offer intelligent results. This is what is known as Inference.
So, first you must feed the beast so to speak, and “train” the AI before it can “infer” or offer meaningful, accurate information to you, the end user. At the edge, or end user level, most of the AI processing being done is inferencing. While some data is gathered, transmitted to the cloud and learned from to enhance the networks, the bulk of AI training is done in the data center. So, in general, for your smartphone’s AI engine, inferencing is its primary workload, though some basic training is done to tailor experiences to individual users as well.
Making Sense Of Mobile Benchmarks For Artificial Intelligence
Machine Learning and AI application development is happening at a breakneck pace. The associated frameworks, hardware, and the trained neural networks that run on them are constantly advancing, which can make it difficult for most people to determine which solutions would be best suited to their particular use case or application. The training and inference processes have very different compute requirements, and the level of accuracy required for a particular application to perform adequately may require a certain specialized type of math or level of precision.A number of ML / AI-related benchmarks have been developed in an attempt to help users navigate the waters and make more informed decisions, especially for mobile devices where AI has numerous potential use cases, from fun image filters and overlays to critical medical and enterprise applications.

We contacted David Kanter, MLPerf Inference Co-Chair, for some third-party perspective, input, and opinions on ML / AI-related mobile benchmarks, and the importance of AI / ML for the average consumer smartphone experience, now and in the future. Kanter offered some interesting insight, noting, “Today, I see many applications of ML in smartphones – auto-completion, speech-to-text, voice activation, translation, and a lot of computer vision such as segmentation or object detection. I tend to believe we are in the early days of ML, and expect to see applications increase over time, especially as ML capabilities become more common in smartphones.”
That said, the AI-related benchmarks currently available often behave very differently from each other. As you might imagine, AI is a relatively new frontier and as such there will be terrain yet untraveled and lots of new things to learn. Which neural networks are utilized by your device and how they’re processed, are determined by the app developer, whether it’s Google’s Assistant or Amazon’s Alexa, for example. Common neural networks used in many of today’s benchmarks include ResNet-34 and Inception-V3 for image classification, Mobilenet-SSD for single-shot object detection and mobile vision, and Google’s DeepLab-v3 for semantic image segmentation, among others.
Further on the subject, in an attempt to provide some clarity on the topic of AI benchmarks for mobile devices (special thanks to Myriam Joire for a hand with a few of the tests), we reached out to a number of developers with questions regarding their apps, but unfortunately received little feedback for most of them. As we dig into some of the popular benchmarks currently available, we’ve incorporated comments from the developers where applicable.
Exploring Current Mobile AI Benchmarks
The AIMark benchmark uses the ResNet-34, Inception-V3, Mobilenet-SSD, and DeepLab-v3+ models for image classification, image recognition, and image segmentation. AIMark’s scores are determined by how efficiently the mobile platform processes the datasets and performs specific object recognition.The current version of the app available in the Play Store leverages Qualcomm’s platform software development kit, the Qualcomm Neural Processing SDK. This is a common SDK employed in many Android phones currently, due to the pervasiveness of Qualcomm’s Snapdragon platforms.

The Samsung Galaxy S20 Is Powered By Qualcomm's Latest Snapdragon Mobile Platform
AIMark’s developer, Ludashi, offered this when we asked them for additional detail on their benchmark, “AImark mainly uses integer neural network models to determine the soc/mobile-device's AI performance. There are many constraints to porting the AI models and tasks to Mobile devices, and lots of mobile NPU-SOCs are only designed for INT8/FP16 mode. Secondly, Mobile devices mainly use AI-models in some practical scenarios, so INT8 is actually widely used. The goal of AImark is to evaluate AI performance of using hardware in real-world scenarios, while supporting all devices as much as possible and being easy to use.”
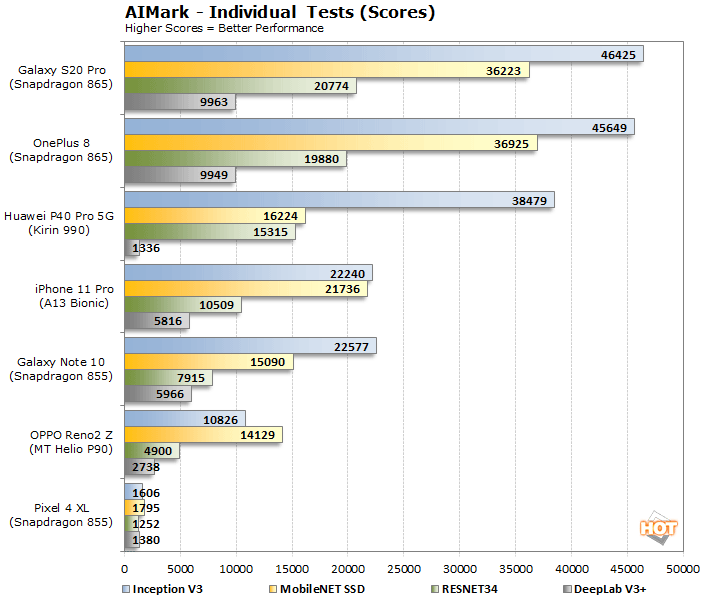
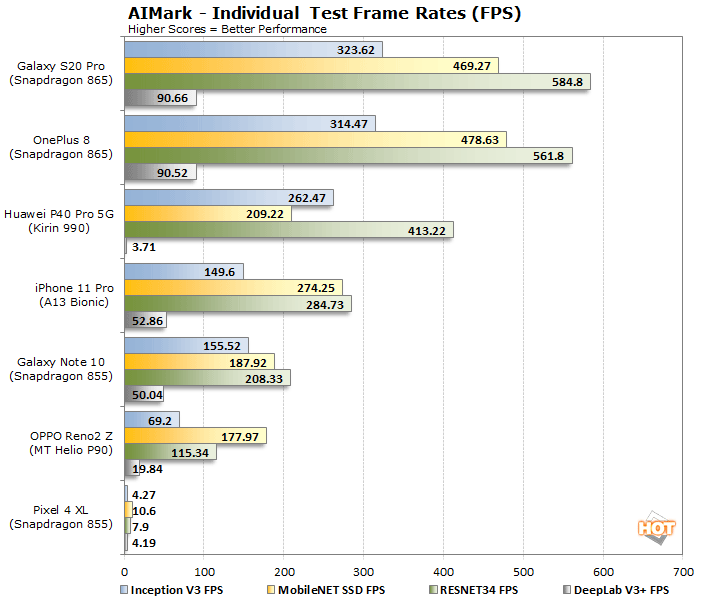
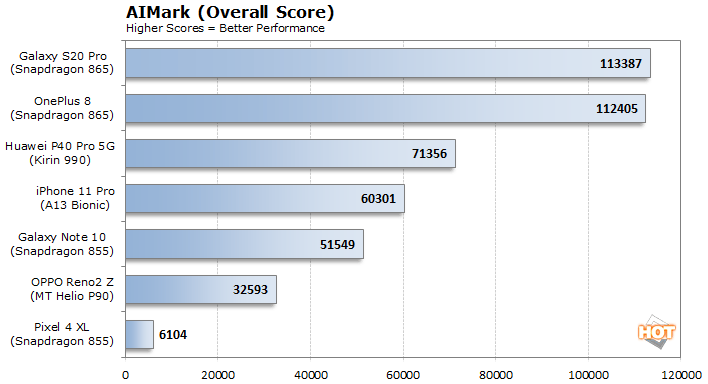
We’ve got an array of devices represented here, based on some of today’s most popular mobile platforms. The benchmark’s use of Qualcomm’s SDK obviously pays huge dividends on the company’s latest Snapdragon 865 Mobile Platform, which is outfitted with a much more powerful fifth-generation AI Engine than its predecessors. The Galaxy S20 Pro and OnePlus 8 significantly outpace all of the other devices by a wide margin as a result. It’s also interesting to note that despite being powered by the same SoC (the Snapdragon 855), the Pixel 4 XL and Galaxy Note 10 have very disparate performance profiles, due to their different software configurations and support for various neural network operations. The MediaTek-powered OPPO device trails the Note 10 by a wide margin, but we are dubious of even that lowly MediaTek result due to the benchmark-boosting whitelisting that was recently brought to light.
Due to some issues with its parent company, the AITuTu benchmark is no longer available in the Google Play Store, but its APK can be easily download from the developer’s website. AITuTu uses the Inception-v3 Neural Network for Image Classification and MobileNet-SSD for Object Detection. It determines a mobile platform’s performance based on the speed and how accurately the device can process the data.
We reached out to the developers of AITuTu for additional information and clarity on their app, but did not receive any replies, unfortunately. AITuTu likely employs some version of Qualcomm’s SDK as well, as evidenced by the results presented here.
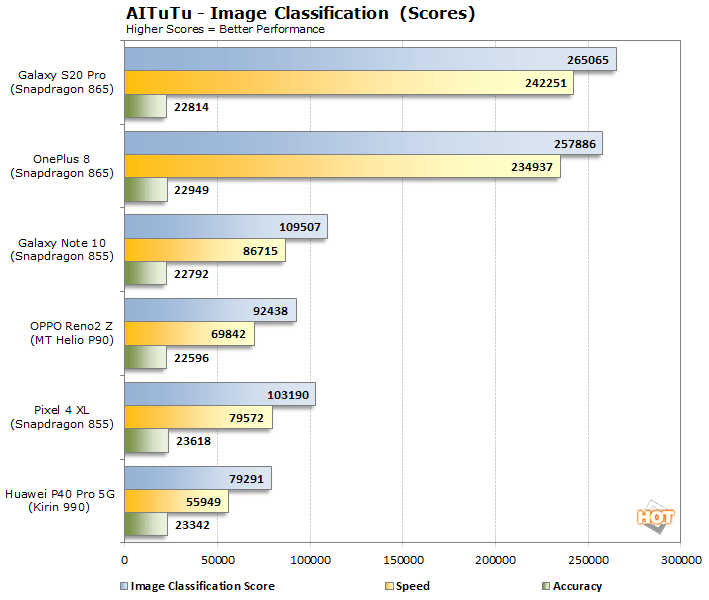
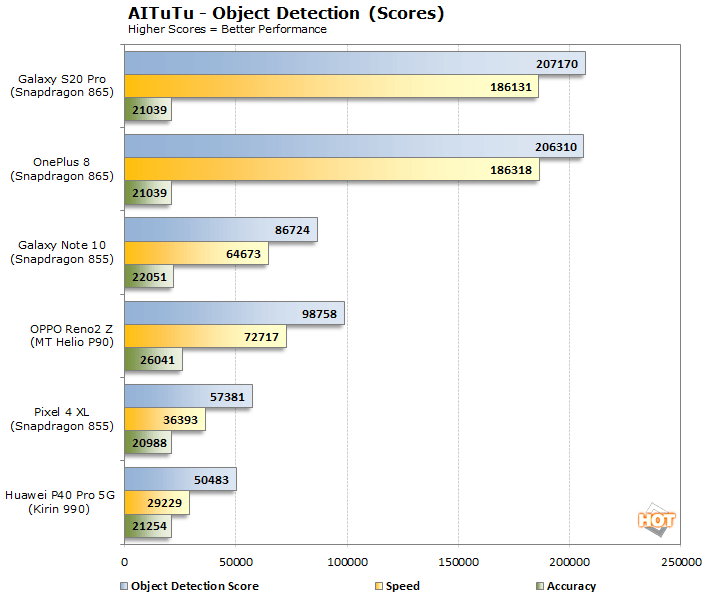
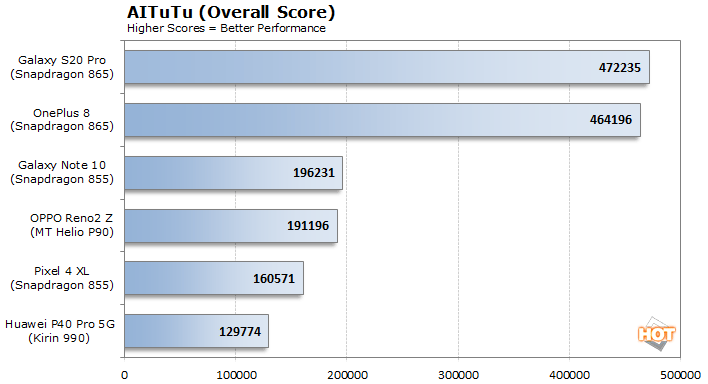
AITuTu also shows the Qualcomm Snapdragon 865-powered devices outperforming the other mobile platforms by a wide margin. AITuTu actually shows the Snapdragon 865 outpacing the last place finisher, the Kirin 990, by nearly 3.6X.
Next up we have AI Benchmark. According to the developers, “AI Benchmark measures the speed, accuracy and memory requirements for several key AI and Computer Vision algorithms. Among the tested solutions are Image Classification and Face Recognition methods, Neural Networks used for Image Super-Resolution and Photo Enhancement, AI models playing Atari Games and performing Bokeh Simulation, as well as algorithms used in autonomous driving systems. Visualization of the algorithms’ output allows to assess their results graphically and to get to know the current state-of-the-art in various AI fields.” The developers also notes that hardware acceleration should be supported on Android 9.0 and higher, on all mobile SoCs with AI accelerators, including Qualcomm Snapdragon, HiSilicon Kirin, Samsung Exynos, and MediaTek Helio. However, unlike the previous benchmarks, AI Benchmark uses TensorFlow Lite (TFLite) and Android’s Neural Network API (NNAPI). This is an important consideration, that has a significant and meaningful impact on the performance scores reported by AI Benchmark.
Over the course of producing this article, two version of the AI Benchmark were made available (v3 and v4), and though the workloads are similar, the two versions are geared and optimized for the various mobile platforms very differently and produce results and scores that can’t be directly compared.
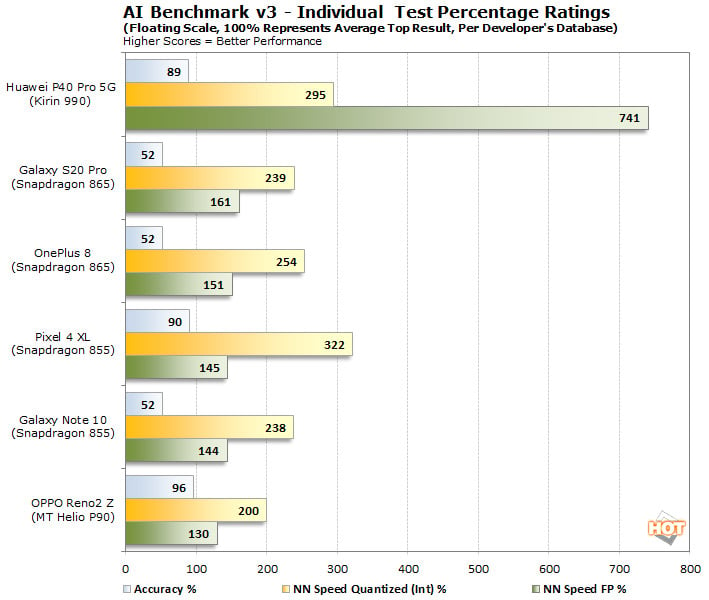
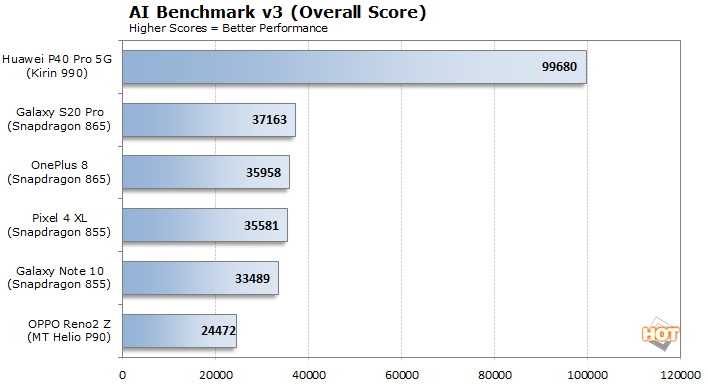
AI Benchmark v3 tells a completely different story than the previous two benchmarks we ran. This particular version of the benchmark places a heavy emphasis on Floating Point performance when determining its final score. The Kirin 990 has a dedicated AI processor optimized for FP operations, couple that with the odd weightings used in this benchmark and the Kirin 990 jumps way out in front. Conversely, the other platforms are stronger with Integer workloads.
When asked why v3 of the benchmarks was set up this way, the developer responded with, “We are discussing the scoring system regularly with all mobile SoC vendors, and are adjusting it based on the obtained feedback. The two most important factors affecting the weightings are (1) The applicability of each model / inference type for mobile devices -- Among the two models showing the same accuracy, the faster and less power-consuming architecture is always preferred. (2) The possibility of applying the model / inference type to the considered task. If the resulting deep learning architecture is very fast, but cannot achieve the target accuracy, it will be either not included in the benchmark, or its weight will be reduced. This is the reason why quantized models are currently scored lower compared to the floating-point ones (though their weight will be increased in the upcoming benchmark version).”
AI Benchmark v3’s results seemed unbalanced to us. Before we completed this article though, a beta of AI Benchmark v4 was made publicly available via the Google Play Store. Let’s have a look at AI Benchmark v4’s results on the same devices...
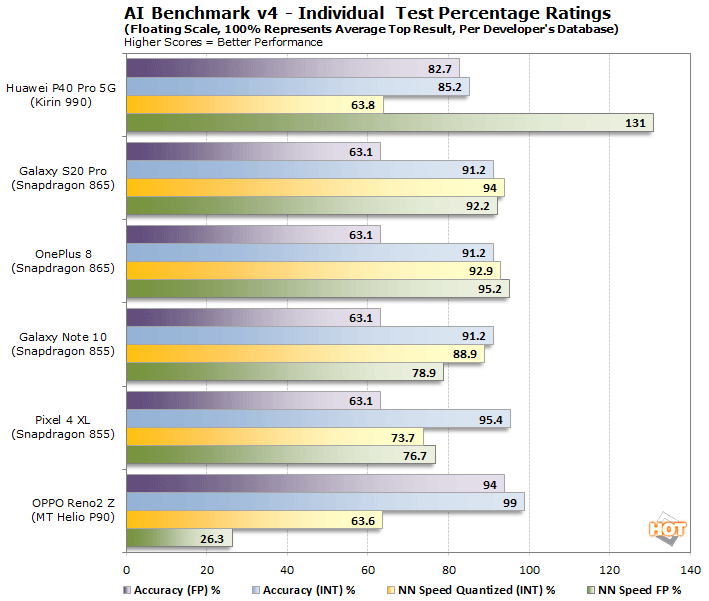

AI Benchmark v4 offers up very different results. The overall trend is unchanged, but the scale of the Kirin 990’s victory is drastically reduced. The benchmark still places a heavier weighting on floating point results, but now incorporates additional frameworks, which perform quite differently, depending on a particular device’s implementation.
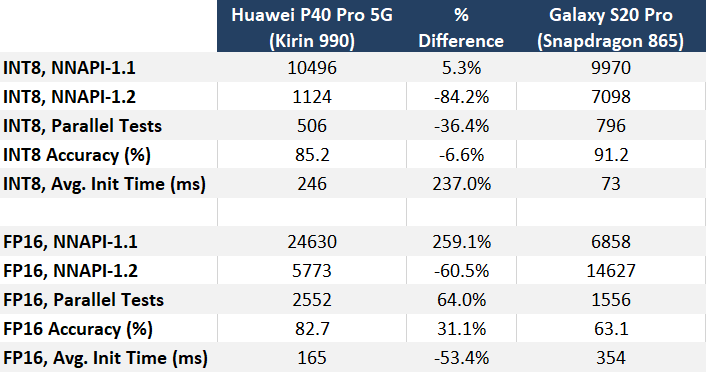
** % Difference shows the advantage / disadvantage(-) of Kirin 990 vs. Snapdragon 865
*** Lower Avg. Init Times (ms) are better
If we look at the fastest two devices in our AI Benchmark v4 results, and break-out the individual integer and floating-point scores, you can clearly see where each device excels. It appears Huawei hasn’t implemented support for some of the NNAPI-1.2 models added in Android 10, whereas Samsung has. Also note, Qualcomm’s AI Engine is optimized for INT8, and as a result the Samsung devices offer better INT8 performance with the newest models, with increased accuracy as well. The scales tip in favor of Huawei in the FP16 tests, however.

The Huawei P40 Pro 5G Featuring The Kirin 990
When asked for an opinion on what the proper weighting for AI / ML performance benchmark should look like for mobile devices, MLPerf’s Kanter had this to say, “Generally, MLPerf has a policy that we do not weight the benchmarks within our suites to produce a summary score. Not all ML tasks are equally important for all systems, and the job of weighting some more heavily than others is highly subjective. For example, my parents extensively use speech-to-text, but rarely take photos. When I visited China, I was constantly taking pictures and also using offline translation on my smartphone. No summary score can capture those two experiences.”
Wrapping It Up – Mobile AI Benchmarks, What They Measure And Why It Matters
What makes for proper AI benchmarking on mobile and other edge devices is the $64,000 question. Artificial Intelligence and Machine Learning are rapidly evolving fields, so to say benchmarks are a moving target would be an understatement. However, there are a few take-aways from our endeavor that users should keep in mind, and Mr. Kanter seems to agree. When asked if consumers should be concerned with ML / AI related benchmarks and what performance characteristics they should be considering, Kanter said, “Absolutely. I think ML capabilities in client systems drive some key applications today, and that will only become more common in the future. When we talk about systems consumers buy, like smartphones, or PCs, more often than not we are talking about inference, rather than training. First is the notion of understanding the benchmark’s workloads and its weighting, as they relate to real-world performance in applications that make use of AI or ML to deliver cutting-edge experiences.”In our testing of the three benchmark utilities here, there’s a clear delineation line between INT8 (Quantization) and FP16 (Floating Point) performance. Two of the benchmarks we utilized rely heavily on INT8 performance (AIMark, AITuTu), while one of them (AI Benchmark) puts much more emphasis on FP16. The simple fact of the matter is, many smartphone applications that employ AI today make use of INT8 with new and advancing quantization techniques, because it’s generally more power-efficient, and there’s nothing worse than an app that rapidly drains battery life. Conversely, INT8 doesn’t have the kind of precision FP16 can deliver, but the real question here is, does that really matter?
Mobile ML / AI Benchmark Considerations And Take-Aways
For all intents and purposes, the majority of Android devices powered by Qualcomm’s latest Snapdragon Mobile Platforms deliver quality experiences driven by INT8 AI precision for speech-to-text, recommendation engines like Google Assistant, and camera image recognition and processing, as well as other applications. Further, Qualcomm’s flagship Snapdragon 865 Mobile Platform cranks that performance up a few notches, versus previous-gen Snapdragon 855 devices. However, when you consider the that picture flips completely in our AI Benchmark tests, which focus more-so on FP16, things likely get confusing for even tech-savvy users, much less mainstream consumers. Here, if you’re a consumer running a Huawei device, you might be fooled into thinking it’s a more powerful AI platform, when the majority of AI-enable apps running on the device aren’t optimized for it.
- INT8 Precision Is More Commonly Employed In Mobile Apps
- INT8 Precision Is Typically More Power Efficient, Conserving Battery Life
- FP16 Offers Higher Precision That May Not Be Required For Most Consumer Applications
- Most Mobile AI Benchmarks Emphasize And Weight INT / FP Performance Differently
Putting it succinctly, FP16 offers better precision, but at the cost of power consumption. FP16 also currently has more limited use in real world apps available on your platform’s app store. Further, enhancements to AI model efficiency and precision with INT8 are improving, to go along with INT8’s power-efficiency advantages as well.
The bottom line for consumers, however, is that the benchmark numbers you’re looking at should equate to real-world performance and precision in the apps you’re likely running on your device. In general, INT8 precision likely satisfies most current mainstream consumer requirements, but you can think of industries like medical and others that might require the precision of FP16. The landscape is going to continue to evolve and benchmark working groups are going to have to track the ever-changing needs of AI and ML-powered apps, and adjust their metrics accordingly. Of course, we’ll continue to sift through the details here at HotHardware, and try to make sense of it all for you moving forward.




